- Java面試題及答案
- Java面向?qū)ο竺嬖囶}
- Java異常處理面試題
- Java常用API面試題
- Java數(shù)據(jù)類型面試題
- Java IO面試題
- Java集合面試題
- 經(jīng)典Java面試題及答案(1~41企業(yè)真題)
- 初級Java工程師面試題(42~81企業(yè)真題)
- Java基礎(chǔ)面試題精選(82~113企業(yè)真題)
- 初級Java程序員面試題(114~130企業(yè)真題)
- Java常見面試題及答案(131~140企業(yè)真題)
- Java經(jīng)典面試題及答案(140~146企業(yè)真題)
- Java基礎(chǔ)邏輯面試題
- Javaweb面試題及答案
- Java前端面試題及答案
- Java linux面試題及答案
- Java框架面試題及答案
- Java mysql面試題
- Java面試題mysql語句優(yōu)化部分
- Java oracle面試題及答案
- Java spring面試題及答案(1~11題)
- Java spring面試題及答案(12~44題)
- Java shiro面試題
- Java mybatis面試題及答案
- Java struts2面試題及答案
- Java Hibernate面試題
- Java初級面試題之Quartz定時任務(wù)
- Java Redis面試題
- Java ActiveMQ面試題
- Java Dubbo面試題
- Java高并發(fā)面試題
- 企業(yè)Java實(shí)戰(zhàn)面試題
- Java多線程和并發(fā)面試題(附答案)1~3題
- Java多線程和并發(fā)面試題(附答案)第4題
- Java多線程和并發(fā)面試題(附答案)第5題
- Java多線程和并發(fā)面試題(附答案)第6題
- Java多線程和并發(fā)面試題(附答案)第6題
- Java多線程和并發(fā)面試題(附答案)7~10題
- Java多線程和并發(fā)面試題(附答案)11~16題
- Java反射面試題及答案
- Java動態(tài)代理面試題及答案
- Java設(shè)計(jì)模式面試題(1~9題)
- Java設(shè)計(jì)模式筆試題(10~13題)
- Java類加載器面試題
- Java GC面試題及答案(1~5題)
- Java GC面試題及答案(第5題)
- Java GC面試題及答案(第5題)
- Java內(nèi)存溢出面試題
- Java內(nèi)存模型面試題
- Java多線程筆試題
- Java集合面試題
- Java mybatis面試題及答案
- Java p2p項(xiàng)目面試題
- Java volatile面試題
- Java線程面試題之線程間的通信方式
Java mysql面試題
1、SQL中聚合函數(shù)有哪些?
聚合函數(shù)是對一組值進(jìn)行計(jì)算并返回單一的值的函數(shù),它經(jīng)常與select語句中的group by子句一同使用。
● avg():返回的是指定組中的平均值,空值被忽略。
● count():返回的是指定組中的項(xiàng)目個數(shù)。
● max():返回指定數(shù)據(jù)中的最大值。
● min():返回指定數(shù)據(jù)中的最小值。
● sum():返回指定數(shù)據(jù)的和,只能用于數(shù)字列,空值忽略。
2、SQL之連接查詢(左連接和右連接的區(qū)別)?
● 外連接:
● 左連接(左外連接):以左表作為基準(zhǔn)進(jìn)行查詢,左表數(shù)據(jù)會全部顯示出來,右表如果和左表匹配的數(shù)據(jù)則顯示相應(yīng)字段的數(shù)據(jù),如果不匹配則顯示為null。
● 右連接(右外連接):以右表作為基準(zhǔn)進(jìn)行查詢,右表數(shù)據(jù)會全部顯示出來,左表如果和右表匹配的數(shù)據(jù)則顯示相應(yīng)字段的數(shù)據(jù),如果不匹配則顯示為null。
● 全連接:先以左表進(jìn)行左外連接,再以右表進(jìn)行右外連接。
● 內(nèi)連接:顯示表之間有連接匹配的所有行。
3、SQL之sql注入是什么?
通過在Web表單中輸入(惡意)SQL語句得到一個存在安全漏洞的網(wǎng)站上的數(shù)據(jù)庫,而不是按照設(shè)計(jì)者意圖去執(zhí)行SQL語句。舉例:當(dāng)執(zhí)行的sql為select * from user where username = “admin” or “a” = “a”時,sql語句恒成立,參數(shù)username毫無意義。
● 防止sql注入的方式:
預(yù)編譯語句:如,select * from user where username = ?,sql語句語義不會發(fā)生改變,sql語句中變量用?表示,即使傳遞參數(shù)時為“admin or ‘a’ = ‘a’”,也會把這整體當(dāng)做一個字符創(chuàng)去查詢。
Mybatis框架中的mapper方式中的#也能很大程度的防止sql注入($無法防止sql注入)。
4、MySQL性能優(yōu)化有哪些?
● 當(dāng)只要一行數(shù)據(jù)時使用limit 1
查詢時如果已知會得到一條數(shù)據(jù),這種情況下加上limit 1會增加性能。因?yàn)镸ySQL數(shù)據(jù)庫引擎會在找到一條結(jié)果停止搜索,而不是繼續(xù)查詢下一條是否符合標(biāo)準(zhǔn)直到所有記錄查詢完畢。
● 選擇正確的數(shù)據(jù)庫引擎
MySQL中有兩個引擎MyISAM和InnoDB,每個引擎有利有弊。MyISAM適用于一些大量查詢的應(yīng)用,但對于有大量寫功能的應(yīng)用不是很好。甚至你只需要update一個字段整個表都會被鎖起來。而別的進(jìn)程就算是讀操作也不行要等到當(dāng)前update操作完成之后才能繼續(xù)進(jìn)行。另外,MyISAM對于select count(*)這類操作是超級快的。InnoDB的趨勢會是一個非常復(fù)雜的存儲引擎,對于一些小的應(yīng)用會比MyISAM還慢,但是支持“行鎖”,所以在寫操作比較多的時候會比較優(yōu)秀。并且,它支持很多的高級應(yīng)用,例如:事務(wù)。
● 用not exists代替not in
not exists用到了連接能夠發(fā)揮已經(jīng)建立好的索引的作用,not in不能使用索引。not in是最慢的方式要同每條記錄比較,在數(shù)據(jù)量比較大的操作紅不建議使用這種方式。
● 對操作符的優(yōu)化,盡量不采用不利于索引的操作符
如:in、not in、is null、is not null 、<> 等某個字段總要拿來搜索,為其建立索引:MySQL中可以利用alter table語句來為表中的字段添加索引,語法為:alter table表名add index(字段名)
5、MySQL 數(shù)據(jù)庫架構(gòu)圖了解嗎?
MyISAM和InnoDB是最常見的兩種存儲引擎,特點(diǎn)如下。
● MyISAM存儲引擎
MyISAM是MySQL官方提供默認(rèn)的存儲引擎,其特點(diǎn)是不支持事務(wù)、表鎖和全文索引,對于一些OLAP(聯(lián)機(jī)分析處理)系統(tǒng),操作速度快。
每個MyISAM在磁盤上存儲成三個文件。文件名都和表名相同,擴(kuò)展名分別是.frm(存儲表定義)、.MYD(MYData,存儲數(shù)據(jù))、.MYI(MYIndex,存儲索引)。這里特別要注意的是MyISAM不緩存數(shù)據(jù)文件,只緩存索引文件。
● InnoDB存儲引擎
InnoDB存儲引擎支持事務(wù),主要面向OLTP(聯(lián)機(jī)事務(wù)處理過程)方面的應(yīng)用,其特點(diǎn)是行鎖設(shè)置、支持外鍵,并支持類似于Oracle的非鎖定讀,即默認(rèn)情況下讀不產(chǎn)生鎖。InnoDB將數(shù)據(jù)放在一個邏輯表空間中(類似Oracle)。
InnoDB通過多版本并發(fā)控制來獲得高并發(fā)性,實(shí)現(xiàn)了ANSI標(biāo)準(zhǔn)的4種隔離級別,默認(rèn)為Repeatable,使用一種被稱為next-keylocking的策略避免幻讀。
對于表中數(shù)據(jù)的存儲,InnoDB采用類似Oracle索引組織表Clustered的方式進(jìn)行存儲。InnoDB存儲引擎提供了具有提交、回滾和崩潰恢復(fù)能力的事務(wù)安全。但是對比myisam的存儲引擎,InnoDB寫的處理效率差一些并且會占用更多的磁盤空間以保留數(shù)據(jù)和索引。以下是InnoDB體系架構(gòu):
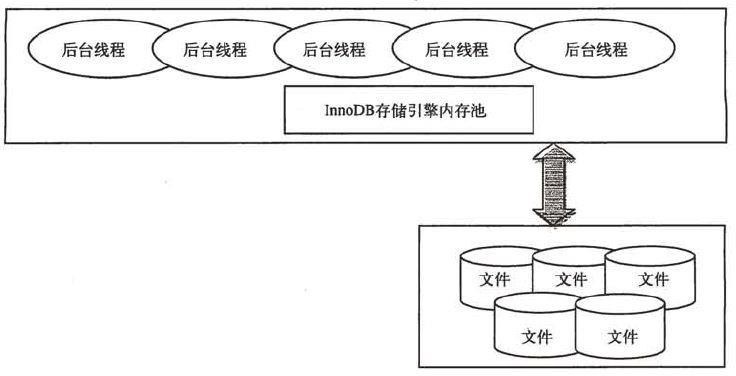
6、MySQL架構(gòu)器中各個模塊都是什么?
● 連接管理與安全驗(yàn)證是什么
每個客戶端都會建立一個與服務(wù)器連接的線程,服務(wù)器會有一個線程池來管理這些連接;如果客戶端需要連接到MYSQL數(shù)據(jù)庫還需要進(jìn)行驗(yàn)證,包括用戶名、密碼、主機(jī)信息等。
● 解析器是什么
解析器的作用主要是分析查詢語句,最終生成解析樹;首先解析器會對查詢語句的語法進(jìn)行分析,分析語法是否有問題。還有解析器會查詢緩存,如果在緩存中有對應(yīng)的語句,就返回查詢結(jié)果不進(jìn)行接下來的優(yōu)化執(zhí)行操作。前提是緩存中的數(shù)據(jù)沒有被修改,當(dāng)然如果被修改了也會被清出緩存。
● 優(yōu)化器怎么用
優(yōu)化器的作用主要是對查詢語句進(jìn)行優(yōu)化操作,包括選擇合適的索引,數(shù)據(jù)的讀取方式,包括獲取查詢的開銷信息,統(tǒng)計(jì)信息等,這也是為什么圖中會有優(yōu)化器指向存儲引擎的箭頭。之前在別的文章沒有看到優(yōu)化器跟存儲引擎之間的關(guān)系,在這里我個人的理解是因?yàn)閮?yōu)化器需要通過存儲引擎獲取查詢的大致數(shù)據(jù)和統(tǒng)計(jì)信息。
● 執(zhí)行器是什么
執(zhí)行器包括執(zhí)行查詢語句,返回查詢結(jié)果,生成執(zhí)行計(jì)劃包括與存儲引擎的一些處理操作。
7、MySQL存儲引擎有哪些?
● InnoDB存儲引擎
InnoDB是事務(wù)型數(shù)據(jù)庫的首選引擎,支持事務(wù)安全表(ACID),支持行鎖定和外鍵,InnoDB是默認(rèn)的MySQL引擎。
● MyISAM存儲引擎
MyISAM基于ISAM存儲引擎,并對其進(jìn)行擴(kuò)展。它是在Web、數(shù)據(jù)倉儲和其他應(yīng)用環(huán)境下最常使用的存儲引擎之一。MyISAM擁有較高的插入、查詢速度,但不支持事務(wù)。
● MEMORY存儲引擎
MEMORY存儲引擎將表中的數(shù)據(jù)存儲到內(nèi)存中,未查詢和引用其他表數(shù)據(jù)提供快速訪問。
● NDB存儲引擎
NDB存儲引擎是一個集群存儲引擎,類似于Oracle的RAC,但它是ShareNothing的架構(gòu),因此能提供更高級別的高可用性和可擴(kuò)展性。NDB的特點(diǎn)是數(shù)據(jù)全部放在內(nèi)存中,因此通過主鍵查找非常快。關(guān)于NDB,有一個問題需要注意,它的連接(join)操作是在MySQL數(shù)據(jù)庫層完成,不是在存儲引擎層完成,這意味著,復(fù)雜的join操作需要巨大的網(wǎng)絡(luò)開銷,查詢速度會很慢。
● Memory(Heap)存儲引擎
Memory存儲引擎(之前稱為Heap)將表中數(shù)據(jù)存放在內(nèi)存中,如果數(shù)據(jù)庫重啟或崩潰,數(shù)據(jù)丟失,因此它非常適合存儲臨時數(shù)據(jù)。
● Archive存儲引擎
正如其名稱所示,Archive非常適合存儲歸檔數(shù)據(jù),如日志信息。它只支持INSERT和SELECT操作,其設(shè)計(jì)的主要目的是提供高速的插入和壓縮功能。
● Federated存儲引擎
Federated存儲引擎不存放數(shù)據(jù),它至少指向一臺遠(yuǎn)程MySQL數(shù)據(jù)庫服務(wù)器上的表,非常類似于Oracle的透明網(wǎng)關(guān)。
● Maria存儲引擎
Maria存儲引擎是新開發(fā)的引擎,其設(shè)計(jì)目標(biāo)是用來取代原有的MyISAM存儲引擎,從而成為MySQL默認(rèn)的存儲引擎。
上述引擎中,InnoDB是事務(wù)安全的存儲引擎,設(shè)計(jì)上借鑒了很多Oracle的架構(gòu)思想,一般而言,在OLTP應(yīng)用中,InnoDB應(yīng)該作為核心應(yīng)用表的首先存儲引擎。InnoDB是由第三方的InnobaseOy公司開發(fā),現(xiàn)已被Oracle收購,創(chuàng)始人是HeikkiTuuri,芬蘭赫爾辛基人,和著名的Linux創(chuàng)始人Linus是校友。
8、MySQL事務(wù)介紹?
MySQL和其它的數(shù)據(jù)庫產(chǎn)品有一個很大的不同就是事務(wù)由存儲引擎所決定,例如MYISAM,MEMORY,ARCHIVE都不支持事務(wù),事務(wù)就是為了解決一組查詢要么全部執(zhí)行成功,要么全部執(zhí)行失敗。MySQL事務(wù)默認(rèn)是采取自動提交的模式,除非顯示開始一個事務(wù)。
SHOW VARIABLES LIKE 'AUTOCOMMIT';
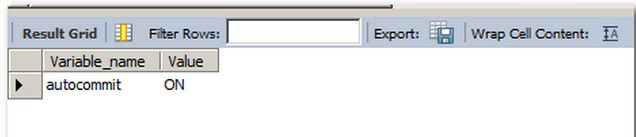
修改自動提交模式,0=OFF,1=ON,注意:修改自動提交對非事務(wù)類型的表是無效的,因?yàn)樗鼈儽旧砭蜎]有提交和回滾的概念,還有一些命令是會強(qiáng)制自動提交的,比如DLL命令、locktables等。
SET AUTOCOMMIT = 0;
或
SET AUTOCOMMIT = OFF;
9、事務(wù)的四大特征是什么?
數(shù)據(jù)庫事務(wù)transanction正確執(zhí)行的四個基本要素。ACID,原子性(Atomicity)、一致性(Correspondence)、隔離性(Isolation)、持久性(Durability)。
● 原子性:整個事務(wù)中的所有操作,要么全部完成,要么全部不完成,不可能停滯在中間某個環(huán)節(jié)。事務(wù)在執(zhí)行過程中發(fā)生錯誤,會被回滾(Rollback)到事務(wù)開始前的狀態(tài),就像這個事務(wù)從來沒有執(zhí)行過一樣。
● 一致性:在事務(wù)開始之前和事務(wù)結(jié)束以后,數(shù)據(jù)庫的完整性約束沒有被破壞。
● 隔離性:隔離狀態(tài)執(zhí)行事務(wù),使它們好像是系統(tǒng)在給定時間內(nèi)執(zhí)行的唯一操作。如果有兩個事務(wù),運(yùn)行在相同的時間內(nèi),執(zhí)行相同的功能,事務(wù)的隔離性將確保每一事務(wù)在系統(tǒng)中認(rèn)為只有該事務(wù)在使用系統(tǒng)。這種屬性有時稱為串行化,為了防止事務(wù)操作間的混淆,必須串行化或序列化請求,使得在同一時間僅有一個請求用于同一數(shù)據(jù)。
● 持久性:在事務(wù)完成以后,該事務(wù)所對數(shù)據(jù)庫所作的更改便持久的保存在數(shù)據(jù)庫之中,并不會被回滾。
10、MySQL中四種隔離級別分別是什么?
● 讀未提交(READ UNCOMMITTED):未提交讀隔離級別也叫讀臟,就是事務(wù)可以讀取其它事務(wù)未提交的數(shù)據(jù)。
● 讀已提交(READ COMMITTED):在其它數(shù)據(jù)庫系統(tǒng)比如SQL Server默認(rèn)的隔離級別就是提交讀,已提交讀隔離級別就是在事務(wù)未提交之前所做的修改其它事務(wù)是不可見的。
● 可重復(fù)讀(REPEATABLE READ):保證同一個事務(wù)中的多次相同的查詢的結(jié)果是一致的,比如一個事務(wù)一開始查詢了一條記錄然后過了幾秒鐘又執(zhí)行了相同的查詢,保證兩次查詢的結(jié)果是相同的,可重復(fù)讀也是MySQL的默認(rèn)隔離級別。
● 可串行化(SERIALIZABLE):可串行化就是保證讀取的范圍內(nèi)沒有新的數(shù)據(jù)插入,比如事務(wù)第一次查詢得到某個范圍的數(shù)據(jù),第二次查詢也同樣得到了相同范圍的數(shù)據(jù),中間沒有新的數(shù)據(jù)插入到該范圍中。
11、MySQL怎么創(chuàng)建存儲過程?
MySQL存儲過程是從MySQL5.0開始增加的新功能。存儲過程的優(yōu)點(diǎn)有一籮筐。不過最主要的還是執(zhí)行效率和SQL代碼封裝。特別是SQL代碼封裝功能,如果沒有存儲過程,在外部程序訪問數(shù)據(jù)庫時,要組織很多SQL語句。特別是業(yè)務(wù)邏輯復(fù)雜的時候,一大堆的SQL和條件夾雜在代碼中,讓人不寒而栗。現(xiàn)在有了MySQL存儲過程,業(yè)務(wù)邏輯可以封裝存儲過程中,這樣不僅容易維護(hù),而且執(zhí)行效率也高。
● 創(chuàng)建MySQL存儲過程
下面代碼創(chuàng)建了一個叫pr_add的MySQL存儲過程,這個MySQL存儲過程有兩個int類型的輸入?yún)?shù)“a”、“b”,返回這兩個參數(shù)的和。
● drop procedure if exists pr_add;(備注:如果存在pr_add的存儲過程,則先刪掉)
● 計(jì)算兩個數(shù)之和(備注:實(shí)現(xiàn)計(jì)算兩個整數(shù)之和的功能)
create procedure pr_add (a int,b int)
begin
declare c int;
if a is null then set a = 0;
end if;
if b is null then set b = 0;
end if;
set c = a + b;
select c as sum;
● 調(diào)用 MySQL 存儲過程
call pr_add(10, 20);
12、MySQL觸發(fā)器怎么寫?
MySQL包含對觸發(fā)器的支持。觸發(fā)器是一種與表操作有關(guān)的數(shù)據(jù)庫對象,當(dāng)觸發(fā)器所在表上出現(xiàn)指定事件時,將調(diào)用該對象,即表的操作事件觸發(fā)表上的觸發(fā)器的執(zhí)行。
在MySQL中,創(chuàng)建觸發(fā)器語法如下:
CREATE TRIGGER trigger_name trigger_time
trigger_event ON tbl_name FOR EACH ROW
trigger_stmt
其中:
trigger_name:標(biāo)識觸發(fā)器名稱,用戶自行指定;
trigger_time:標(biāo)識觸發(fā)時機(jī),取值為BEFORE或AFTER;
trigger_event:標(biāo)識觸發(fā)事件,取值為INSERT、UPDATE或DELETE;
tbl_name:標(biāo)識建立觸發(fā)器的表名,即在哪張表上建立觸發(fā)器;
trigger_stmt:觸發(fā)器程序體,可以是一句SQL語句,或者用BEGIN和END包含的多條語句。
由此可見,可以建立6種觸發(fā)器,即:BEFOREINSERT、BEFOREUPDATE、BEFOREDELETE、AFTERINSERT、AFTERUPDATE、AFTERDELETE。
另外有一個限制是不能同時在一個表上建立2個相同類型的觸發(fā)器,因此在一個表上最多建立6個觸發(fā)器。假設(shè)系統(tǒng)中有兩個表:
● 班級表class(班級號classID,班內(nèi)學(xué)生數(shù)stuCount)
● 學(xué)生表student(學(xué)號stuID,所屬班級號classID)
要創(chuàng)建觸發(fā)器來使班級表中的班內(nèi)學(xué)生數(shù)隨著學(xué)生的添加自動更新,代碼如下:
create trigger tri_stuInsert after insert on student for each row
begin
declare c int;
set c = (select stuCount from class where classID=new.classID);
update class set stuCount = c + 1 where classID = new.classID;
查看觸發(fā)器:和查看數(shù)據(jù)庫(showdatabases;)查看表格(showtables;)一樣,查看觸發(fā)器的語法如下:
SHOW TRIGGERS [FROM schema_name];
其中,schema_name即Schema的名稱,在MySQL中Schema和Database是一樣的,也就是說,可以指定數(shù)據(jù)庫名,這樣就不必先“USE database_name;”了。
刪除觸發(fā)器:和刪除數(shù)據(jù)庫、刪除表格一樣,刪除觸發(fā)器的語法如下:
DROP TRIGGER [IF EXISTS] [schema_name.]trigger_name
其中,schema_name即Schema的名稱,在MySQL中Schema和Database是一樣的,也就是說,可以指定數(shù)據(jù)庫名,這樣就不必先“USEdatabase_name;”了。






