- Java面試題及答案
- Java面向對象面試題
- Java異常處理面試題
- Java常用API面試題
- Java數據類型面試題
- Java IO面試題
- Java集合面試題
- 經典Java面試題及答案(1~41企業真題)
- 初級Java工程師面試題(42~81企業真題)
- Java基礎面試題精選(82~113企業真題)
- 初級Java程序員面試題(114~130企業真題)
- Java常見面試題及答案(131~140企業真題)
- Java經典面試題及答案(140~146企業真題)
- Java基礎邏輯面試題
- Javaweb面試題及答案
- Java前端面試題及答案
- Java linux面試題及答案
- Java框架面試題及答案
- Java mysql面試題
- Java面試題mysql語句優化部分
- Java oracle面試題及答案
- Java spring面試題及答案(1~11題)
- Java spring面試題及答案(12~44題)
- Java shiro面試題
- Java mybatis面試題及答案
- Java struts2面試題及答案
- Java Hibernate面試題
- Java初級面試題之Quartz定時任務
- Java Redis面試題
- Java ActiveMQ面試題
- Java Dubbo面試題
- Java高并發面試題
- 企業Java實戰面試題
- Java多線程和并發面試題(附答案)1~3題
- Java多線程和并發面試題(附答案)第4題
- Java多線程和并發面試題(附答案)第5題
- Java多線程和并發面試題(附答案)第6題
- Java多線程和并發面試題(附答案)第6題
- Java多線程和并發面試題(附答案)7~10題
- Java多線程和并發面試題(附答案)11~16題
- Java反射面試題及答案
- Java動態代理面試題及答案
- Java設計模式面試題(1~9題)
- Java設計模式筆試題(10~13題)
- Java類加載器面試題
- Java GC面試題及答案(1~5題)
- Java GC面試題及答案(第5題)
- Java GC面試題及答案(第5題)
- Java內存溢出面試題
- Java內存模型面試題
- Java多線程筆試題
- Java集合面試題
- Java mybatis面試題及答案
- Java p2p項目面試題
- Java volatile面試題
- Java線程面試題之線程間的通信方式
Java多線程和并發面試題(附答案)7~10題
7、多線程面試題
1.多線程的創建方式
(1)繼承Thread類:但Thread本質上也是實現了Runnable接口的一個實例,它代表一個線程的實例,并且,啟動線程的唯一方法就是通過Thread類的start()實例方法。start()方法是一個native方法,它將啟動一個新線程,并執行run()方法。這種方式實現多線程很簡單,通過自己的類直接extend Thread,并復寫run()方法,就可以啟動新線程并執行自己定義的run()方法。例如:繼承Thread類實現多線程,并在合適的地方啟動線程。
public class MyThread extends Thread {
public void run() {
System.out.println("MyThread.run()");
}
}
MyThread myThread1 = new MyThread();
MyThread myThread2 = new MyThread();
myThread1.start();
myThread2.start();
(2)實現Runnable接口的方式實現多線程,并且實例化Thread,傳入自己的Thread實例,調用run()方法。
public class MyThread implements Runnable {
public void run() {
System.out.println("MyThread.run()");
}
}
MyThread myThread = new MyThread();
Thread thread = new Thread(myThread);
thread.start();
(3)使用ExecutorService、Callable、Future實現有返回結果的多線程:ExecutorService、Callable、Future這個對象實際上都是屬于Executor框架中的功能類。返回結果的線程是在JDK1.5中引入的新特征,確實很實用,有了這種特征我就不需要再為了得到返回值而大費周折了,而且即便實現了也可能漏洞百出。可返回值的任務必須實現Callable接口,類似的,無返回值的任務必須實現Runnable接口。執行Callable任務后,可以獲取一個Future的對象,在該對象上調用get就可以獲取到Callable任務返回的Object了,再結合線程池接口ExecutorService就可以實現有返回結果的多線程了。下面提供了一個完整的有返回結果的多線程測試例子,在JDK1.5下驗證過沒問題可以直接使用。代碼如下:
import java.util.concurrent.*;
import java.util.Date;
import java.util.List;
import java.util.ArrayList;
public class Test {
public static void main(String[] args) throws ExecutionException, InterruptedException{
System.out.println("----程序開始運行----");
Date date1 = new Date();
int taskSize = 5;
// 創建一個線程池
ExecutorService pool = Executors.newFixedThreadPool(taskSize);
// 創建多個有返回值的任務
List<Future> list = new ArrayList<Future>();
for (int i = 0; i < taskSize; i++) {
Callable c = new MyCallable(i + " ");
// 執行任務并獲取 Future 對象
Future f = pool.submit(c);
// System.out.println(">>>" + f.get().toString());
list.add(f);
}
// 關閉線程池
pool.shutdown();
// 獲取所有并發任務的運行結果
for (Future f : list) {
// 從 Future 對象上獲取任務的返回值,并輸出到控制臺
System.out.println(">>>" + f.get().toString());
}
Date date2 = new Date();
System.out.println("----程序結束運行----,程序運行時間【" + (date2.getTime() - date1.getTime()) + "毫秒】");
}
}
class MyCallable implements Callable<Object> {
private String taskNum;
MyCallable(String taskNum) {
this.taskNum = taskNum;
}
public Object call() throws Exception {
System.out.println(">>>" + taskNum + "任務啟動");
Date dateTmp1 = new Date();
Thread.sleep(1000);
Date dateTmp2 = new Date();
long time = dateTmp2.getTime() - dateTmp1.getTime();
System.out.println(">>>" + taskNum + "任務終止");
return taskNum + "任務返回運行結果,當前任務時間【" + time + "毫秒】";
}
}
2.在java中wait和sleep方法的不同?
最大的不同是在等待時wait會釋放鎖,而sleep一直持有鎖。wait通常被用于線程間交互,sleep通常被用于暫停執行。
3.synchronized和volatile關鍵字的作用?
一旦一個共享變量(類的成員變量、類的靜態成員變量)被volatile修飾之后,那么就具備了兩層語義:
● 保證了不同線程對這個變量進行操作時的可見性,即一個線程修改了某個變量的值,這新值對其他線程來說是立即可見的。
● 禁止進行指令重排序。
● volatile本質是在告訴jvm當前變量在寄存器(工作內存)中的值是不確定的,需要從主存中讀取;synchronized則是鎖定當前變量,只有當前線程可以訪問該變量,其他線程被阻塞住。
● volatile僅能使用在變量級別;synchronized則可以使用在變量、方法、和類級別的。
● volatile僅能實現變量的修改可見性,并不能保證原子性;synchronized則可以保證變量的修改可見性和原子性。
● volatile不會造成線程的阻塞;synchronized可能會造成線程的阻塞。
volatile標記的變量不會被編譯器優化;synchronized標記的變量可以被編譯器優化。
4.分析線程并發訪問代碼解釋原因?
public class Counter {
private volatile int count = 0;
public void inc() {
try {
Thread.sleep(3);
} catch (InterruptedException e) {
e.printStackTrace();
}
count++;
}
@Override
public String toString() {
return "[count=" + count + "]";
}
}
public class VolatileTest {
public static void main(String[] args) {
final Counter counter = new Counter();
for (int i = 0; i < 1000; i++) {
new Thread(new Runnable() {
@Override
public void run() {
counter.inc();
}
}).start();
}
System.out.println(counter);
}
}
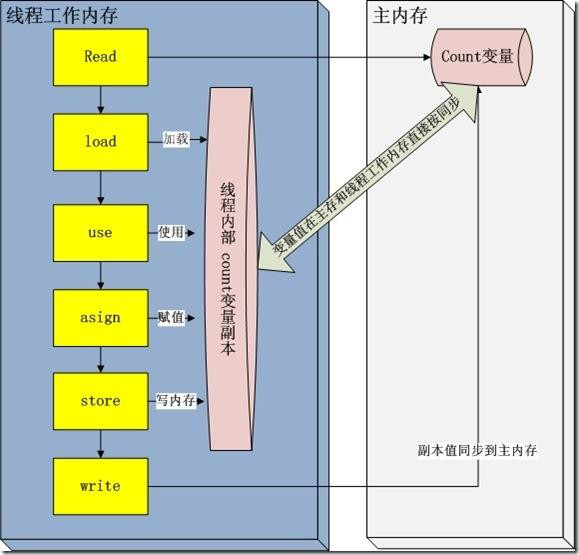
上面的代碼執行完后輸出的結果確定為1000嗎?答案是不一定,或者不等于 1000。你知道這是為什么嗎?
在java的內存模型中每一個線程運行時都有一個線程棧,線程棧保存了線程運行時候變量值信息。當線程訪問某一個對象時候值的時候,首先通過對象的引用找到對應在堆內存的變量的值,然后把堆內存變量的具體值load到線程本地內存中,建立一個變量副本,之后線程就不再和對象在堆內存變量值有任何關系,而是直接修改副本變量的值,在修改完之后的某一個時刻(線程退出之前),自動把線程變量副本的值回寫到對象在堆中變量。這樣在堆中的對象的值就產生變化了。
也就是說上面主函數中開啟了1000個子線程,每個線程都有一個變量副本,每個線程修改變量只是臨時修改了自己的副本,當線程結束時再將修改的值寫入在主內存中,這樣就出現了線程安全問題。因此結果就不可能等于1000了,一般都會小于1000。
上面的解釋用一張圖表示如下:
5.什么是線程池,如何使用?
線程池就是事先將多個線程對象放到一個容器中,當使用的時候就不用new線程而是直接去池中拿線程即可,節省了開辟子線程的時間,提高的代碼執行效率。在JDK的java.util.concurrent.Executors中提供了生成多種線程池的靜態方法。
ExecutorService newCachedThreadPool = Executors.newCachedThreadPool();
ExecutorService newFixedThreadPool = Executors.newFixedThreadPool(4);
ScheduledExecutorService newScheduledThreadPool = Executors.newScheduledThreadPool(4);
ExecutorService newSingleThreadExecutor = Executors.newSingleThreadExecutor();
然后調用他們的 execute 方法即可。
6.常用的線程池有哪些?
● newSingleThreadExecutor:創建一個單線程的線程池,此線程池保證所有任務的執行順序按照任務的提交順序執行。
● newFixedThreadPool:創建固定大小的線程池,每次提交一個任務就創建一個線程,直到線程達到線程池的最大大小。
● newCachedThreadPool:創建一個可緩存的線程池,此線程池不會對線程池大小做限制,線程池大小完全依賴于操作系統(或者說JVM)能夠創建的最大線程大小。
● newScheduledThreadPool:創建一個大小無限的線程池,此線程池支持定時以及周期性執行任務的需求。
● newSingleThreadExecutor:創建一個單線程的線程池。此線程池支持定時以及周期性執行任務的需求。
7. 請敘述一下您對線程池的理解?
(如果問到了這樣的問題,可以展開的說一下線程池如何用、線程池的好處、線程池的啟動策略)合理利用線程池能夠帶來三個好處。
第一:降低資源消耗。通過重復利用已創建的線程降低線程創建和銷毀造成的消耗。
第二:提高響應速度。當任務到達時,任務可以不需要等到線程創建就能立即執行。
第三:提高線程的可管理性。線程是稀缺資源,如果無限制的創建,不僅會消耗系統資源,還會降低系統的穩定性,使用線程池可以進行統一的分配,調優和監控。
8.線程池的啟動策略?
1、線程池剛創建時,里面沒有一個線程。任務隊列是作為參數傳進來的。不過,就算隊列里面有任務,線程池也不會馬上執行它們。
2、當調用execute()方法添加一個任務時,線程池會做如下判斷:
(1)如果正在運行的線程數量小于corePoolSize,那么馬上創建線程運行這個任務;
(2)如果正在運行的線程數量大于或等于corePoolSize,那么將這個任務放入隊列;
(3)如果這時候隊列滿了,而且正在運行的線程數量小于maximumPoolSize,那么還是要創建線程運行這個任務;
(4)如果隊列滿了,而且正在運行的線程數量大于或等于maximumPoolSize,那么線程池會拋出異常,告訴調用者“我不能再接受任務了”。
(5)當一個線程完成任務時,它會從隊列中取下一個任務來執行。
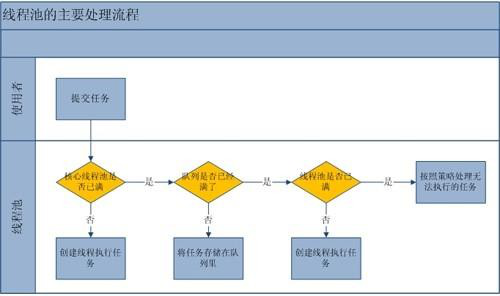
(6)當一個線程無事可做,超過一定的時間(keepAliveTime)時,線程池會判斷,如果當前運行的線程數大于corePoolSize,那么這個線程就被停掉。所以線程池的所有任務完成后,它最終會收縮到corePoolSize的大小。
9.如何控制某個方法允許并發訪問線程的個數?
1.package com.bjpowernode;
2.
3.import java.util.concurrent.Semaphore;
4. /**
5. *
6. * @author dujubin
7. *
8. */
9. public class SemaphoreTest {
10./*
11.* permits the initial number of permits available. This value may be negative,
12.in which case releases must occur before any acquires will be granted.
13.fair true if this semaphore will guarantee first-in first-out granting of
14.permits under contention, else false
15. */
16. static Semaphore semaphore = new Semaphore(5,true);
17. public static void main(String[] args) {
18. for (int i = 0; i < 100; i++) {
19. new Thread(new Runnable()
20. {
21. @Override
22. public void run () {
23. test();
24. }
25. }).start();
26. }
27.
28. }
29.
30. public static void test() {
31. try {
32. //申請一個請求
33. semaphore.acquire();
34. } catch (InterruptedException e1) {
35. e1.printStackTrace();
36. }
37. System.out.println(Thread.currentThread().getName() + "進來了");
38. try {
39. Thread.sleep(1000);
40. } catch (InterruptedException e) {
41. e.printStackTrace();
42. }
43. System.out.println(Thread.currentThread().getName() + "走了");
44. //釋放一個請求
45. semaphore.release();
46. }
47.}
可以使用Semaphore控制,第16行的構造函數創建了一個Semaphore對象,并且初始化了5個信號。這樣的效果是控件test方法最多只能有5個線程并發訪問,對于5個線程時就排隊等待,走一個來一下。第33行,請求一個信號(消費一個信號),如果信號被用完了則等待,第45行釋放一個信號,釋放的信號新的線程就可以使用了。
10.三個線程a、b、c并發運行,b,c需要a線程的數據怎么實現?
根據問題的描述,我將問題用以下代碼演示,ThreadA、ThreadB、ThreadC,ThreadA用于初始化數據num,只有當num初始化完成之后再讓ThreadB和ThreadC獲取到初始化后的變量num。分析過程如下:
考慮到多線程的不確定性,因此我們不能確保ThreadA就一定先于ThreadB和ThreadC前執行,就算ThreadA先執行了,我們也無法保證ThreadA什么時候才能將變量num給初始化完成。因此我們必須讓ThreadB和ThreadC去等待ThreadA完成任何后發出的消息。
現在需要解決兩個難題,一是讓ThreadB和ThreadC等待ThreadA先執行完,二是ThreadA執行完之后給ThreadB和ThreadC發送消息。
解決上面的難題我能想到的兩種方案,一是使用純Java API的Semaphore類來控制線程的等待和釋放,二是使用Android提供的Handler消息機制。
解決方案一:
1. package com.bjpowernode;
2. /**
3. * 三個線程 a、b、c 并發運行,b,c 需要 a 線程的數據怎么實現
4. *
5. */
6.public class ThreadCommunication {
7. private static int num;//定義一個變量作為數據8.
9. public static void main(String[] args) {
10.
11. Thread threadA = new Thread(new Runnable() {
12.
13. @Override
14. public void run() {
15. try {
16. //模擬耗時操作之后初始化變量 num
17. Thread.sleep(1000);
18. num = 1;
19.
20. } catch (InterruptedException e) {
21. e.printStackTrace();
22. }
23. }
24. });
25. Thread threadB = new Thread(new Runnable() {
26.
27. @Override
28. public void run() {
29. System.out.println(Thread.currentThread().getName()+"獲取到 num 的值為:"+num);
30. }
31. });
32. Thread threadC = new Thread(new Runnable() {
33.
34. @Override
35. public void run() {
36. System.out.println(Thread.currentThread().getName()+"獲取到 num 的值為:"+num);
37. }
38. });
39. //同時開啟 3 個線程
40. threadA.start();
41. threadB.start();
42. threadC.start();
43.
44. }
45. }
46.
解決方案二:
ublic class ThreadCommunication {
private static int num;
/**
* 定義一個信號量,該類內部維持了多個線程鎖,可以阻塞多個線程,釋放多個線程,
* 線程的阻塞和釋放是通過 permit 概念來實現的
* 線程通過 semaphore.acquire()方法獲取 permit,如果當前 semaphore 有 permit 則分配給該線程,
* 如果沒有則阻塞該線程直到 semaphore
* 調用 release()方法釋放 permit。
* 構造函數中參數:permit(允許) 個數,
*/
private static Semaphore semaphore = new Semaphore(0);
public static void main(String[] args) {
Thread threadA = new Thread(new Runnable() {
@Override
public void run() {
try {
//模擬耗時操作之后初始化變量 num
Thread.sleep(1000);
num = 1;
//初始化完參數后釋放兩個 permit
semaphore.release(2);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
});
Thread threadB = new Thread(new Runnable() {
@Override
public void run() {
try {
//獲取 permit,如果 semaphore 沒有可用的 permit 則等待,如果有則消耗一個
semaphore.acquire();
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(Thread.currentThread().getName() + "獲取到 num 的值為:" + num);
}
});
Thread threadC = new Thread(new Runnable() {
@Override
public void run() {
try {
//獲取 permit,如果 semaphore 沒有可用的 permit 則等待,如果有則消耗一個
semaphore.acquire();
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(Thread.currentThread().getName() + "獲取到 num 的值為:" + num);
}
});
//同時開啟 3 個線程
threadA.start();
threadB.start();
threadC.start();
}
}






